
🔵 문제 링크
https://school.programmers.co.kr/learn/courses/30/lessons/42861
프로그래머스
SW개발자를 위한 평가, 교육의 Total Solution을 제공하는 개발자 성장을 위한 베이스캠프
programmers.co.kr
🔵 문제 접근
최소 신장 트리를 구현하는 문제이다.
🔵 신장 트리와 최소 신장 트리
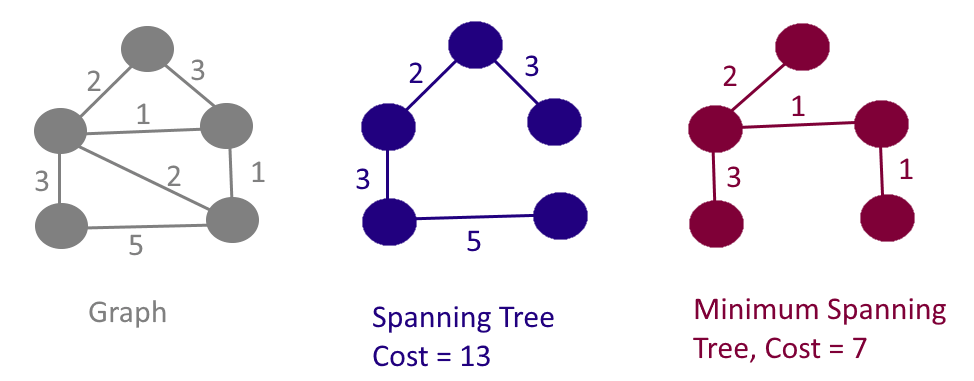
우선, 신장 트리는 무엇일까?
신장 트리란 그래프 상에서 모든 노드가 사이클 없이 연결된 부분 그래프를 뜻한다.
이 부분 그래프는 여러개가 존재할 수 있다.
따라서 최소 신장 트리란 여러 개의 부분 그래프 중 모든 정점이 최소 간선의 합으로 연결된 부분 그래프이다.
(트리는 그래프 중에서 특수한 경우에 해당하는 자료 구조로, 사이클이 존재하지 않는 방향 그래프이다.)
최소 신장 트리는 크루스칼 알고리즘을 통해 찾을 수 있으며, 크루스칼 알고리즘 내에서 union find 알고리즘을 통해 사이클 발생 여부를 판단한다.
🔵 크루스칼 알고리즘
크루스칼 알고리즘은 크게 3단계로 구성되며 2~3이 반복 수행된다.
- 주어진 모든 간선을 오름차순 정렬한다.
- 정렬된 간선을 하나씩 확인하며 현재 간선이 노드 간 사이클을 발생시키는지 확인한다.
- 사이클을 발생시키지 않을 경우 최소 신장 트리에 포함하고, 사이클이 발생할 경우엔 포함하지 않는다.
이때, 사이클 발생 여부를 확인하는 것이 union find 알고리즘이다.
🔵 union find 알고리즘
union find 알고리즘을 배우기에 앞서, disjoint set에 대한 개념을 알고 있어야 한다.
disjoint set이란 공통 원소가 없는, 상호 배타적인 부분 집합들로 나눠진 원소들에 대한 자료 구조이다.
이렇게 말하면 어려울 수가 있는데, 그냥 교집합 없는 원소들의 집합들이다.
union find는 disjoint set을 표현할 때 사용하는 알고리즘이며 트리 구조를 활용하여 쉽게 구현할 수 있다.
크게 필요한 연산은 union, find 연산이 있다.
union 연산은 집합 두 개를 합치는 것이고, find는 해당 원소의 루트 노드를 찾아내는 연산이다.
🔵 배열로 disjoint set 트리 표현하기
매우 간단하다.
어떤 원소가 x이고, 그 원소의 부모가 y일 때 배열[x] = y라고 표현하면 된다.
이를 계속 따라가면 마지막에 루트 노드를 찾을 수 있는 것이다.
disjoint set은 상호 배타적인 집합이므로, 루트 노드를 찾아갈 때까지 다른 집합과 꼬이는 일은 절대 없다.
그래서 find, union 연산을 할 수 있는 것이다.
🔵 find 연산
트리 구조로 disjoint set을 표현했을 때, find 연산으로 각 원소의 루트 노드를 찾아 올라가면 그 원소가 어떤 집합 안에 있는지 알 수 있다.
즉, find 연산에서 루트 노드라는 것은 집합의 대표 원소이며, 어떤 집합에 있는지 확인할 수 있는 요소가 된다.
find(x) == find(y)라면, x와 y는 같은 집합 안에 있는 것이다. 즉, x와 y는 이미 연결되어 있다. (여기서 union 연산을 더 한다면 사이클 발생)
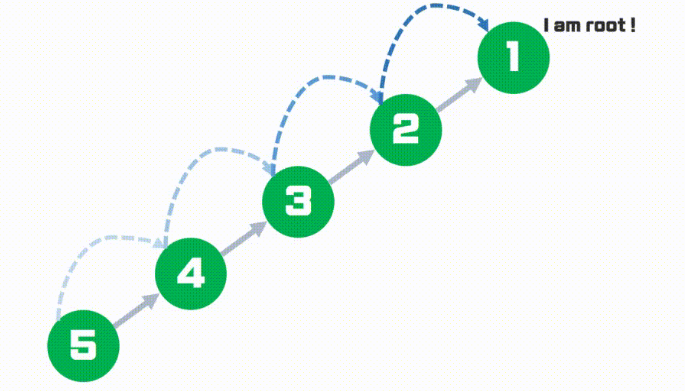
만약 한 집합에서 루트 노드까지의 경로가 너무 길면 어떻게 될까?
그림에서 알 수 있듯이 길면 길수록 비효율적일 것을 예측할 수 있다.
이를 해결할 수 있는 방법이 있는데, 바로 경로 압축이다.
말만 들어선 매우 복잡할 것 같지만 그렇지 않다.
저 그림에서 배열[5] = 4, 배열[4] = 3... 이런식으로 되어 있는 것을 배열[5] = 1로 그냥 한 번에 루트 노드를 찾을 수 있게 하는 것이다.
코드는 다음과 같다.
// 루트 노드 찾기
int find(int x)
{
if (parent[x] == -1)
return x;
// 경로 압축
parent[x] = find(parent[x]);
return parent[x];
}
🔵 union 연산

트리의 높이가 서로 다를 때, 트리를 어떻게 합치는 게 효율적일까?
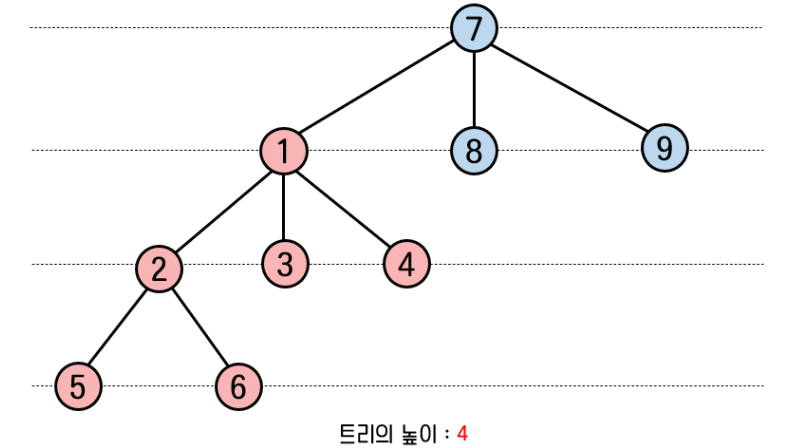
높이가 큰 트리를 작은 트리 밑에 붙인다면... 높이가 더 커질 것이다.
그리고 트리가 불균형해진 것을 알 수 있다.
트리는 균형적일 수록 더 효율적인 자료 구조이다.

높이가 작은 트리를 큰 트리 밑에 붙여 보자.
트리의 높이는 증가하지 않았고, 트리가 균형이 잡힌 모습인 것을 볼 수 있다.
따라서 무턱대고 트리를 합치는 게 아니라, 트리의 rank를 비교해서 큰 쪽에 작은 트리를 붙이는 것이 효율적이다.
위 그림에서 빨간 트리의 rank는 2이고, 파란 트리의 rank는 1이다.
코드로 구현할 경우 다음과 같다.
void makeUnion(int x, int y)
{
int root1 = find(x);
int root2 = find(y);
// 랭크 기반으로 합침 (균형을 위해)
if (root1 != root2)
{
if (rank[root1] < rank[root2])
parent[root1] = root2;
else if (rank[root2] < rank[root1])
parent[root2] = root1;
else
{
parent[root1] = root2;
rank[root2]++;
}
}
}
else 문에서 rank가 서로 같을 경우 아무 트리를 기준으로 서로 합치고, 기준이 된 트리의 루트 노드 rank를 증가시킨다.
아무래도 같은 rank를 합쳤으므로 기준 루트 노드의 rank가 1 증가할 수밖에 없다.
🔵 전체 코드
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
class DisjointSet
{
vector<int> parent;
vector<int> rank;
public:
DisjointSet(int size) : parent(size, -1), rank(size, 0) {}
// 루트 노드 찾기
int find(int x)
{
if (parent[x] == -1)
return x;
// 경로 압축
parent[x] = find(parent[x]);
return parent[x];
}
void makeUnion(int x, int y)
{
int root1 = find(x);
int root2 = find(y);
// 랭크 기반으로 합침 (균형을 위해)
if (root1 != root2)
{
if (rank[root1] < rank[root2])
parent[root1] = root2;
else if (rank[root2] < rank[root1])
parent[root2] = root1;
else
{
parent[root1] = root2;
rank[root2]++;
}
}
}
bool isCycle(int x, int y)
{
return find(x) == find(y);
}
};
int solution(int n, vector<vector<int>> costs)
{
int answer = 0;
DisjointSet dsj(n);
// 건설 비용이 낮은 순으로 정렬
// 건설 비용이 낮은 순으로 다리를 만들고, 불필요한 다리(사이클)를 건설하려 하면 pass
sort(costs.begin(), costs.end(), [](const auto& a, const auto& b) { return a[2] < b[2]; });
for (const auto& edge : costs)
{
int cost = edge[2];
int node1 = edge[0];
int node2 = edge[1];
// 사이클이 없다면 다리를 만든다.
if (!dsj.isCycle(node1, node2))
{
dsj.makeUnion(node1, node2);
answer += cost;
}
}
return answer;
}
🔵 시간 복잡도
N은 노드 개수, E는 costs의 간선의 개수라고 할 때, 간선을 비용 기준으로 정렬할 때 시간 복잡도는 O(ElogE)이다.
그 다음, costs를 순회하면서 find, union 함수를 호출하기 위한 시간 복잡도는 O(E)이다.
(find에서 최적화를 안 했다면 최악의 경우 O(N * E)이다.)
따라서 O(ElogE) + O(E)이므로 최종 시간 복잡도는 O(ElogE)라고 볼 수 있다.
🔵 참고 블로그
https://roytravel.tistory.com/348
[자료구조] 최소 신장 트리와 크루스칼 알고리즘
최소 신장 트리란? 신장 트리란 그래프 상에서 모든 노드가 사이클 없이 연결된 부분 그래프를 뜻한다. 이 부분 그래프는 여러개가 존재할 수 있다. 따라서 최소 신장 트리란 여러 개의 부분 그
roytravel.tistory.com
https://velog.io/@jjhjjh1159/Union-Find-%EC%B5%9C%EC%A0%81%ED%99%94
Union-Find 최적화
일반적으로 Find 연산은 부모 노드를 재귀를 통해 찾아나간다. 또한 Union 연산은 특별한 기준없이 어느 한쪽에 합쳐지게 된다.하지만 매번 find 를 수행한다면 root 노드를 계속해서 찾아나가는 불
velog.io
https://gmlwjd9405.github.io/2018/08/31/algorithm-union-find.html
[알고리즘] Union-Find 알고리즘 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
'PS' 카테고리의 다른 글
| [C++] Programmers Lv. 2 "미로 탈출" (0) | 2025.06.10 |
|---|---|
| [C++] 다익스트라 & 벨만-포드 알고리즘 구현하기 (0) | 2025.06.10 |
| [C++] Programmers Lv. 1 "폰켓몬" (0) | 2025.06.05 |
| [C++] Programmers Lv. 3 "길 찾기 게임" (0) | 2025.06.04 |
| [C++] Programmers Lv. 3 "다단계 칫솔 판매" (0) | 2025.06.04 |